Reproducibility is hard.
Last week I wrote a simple Reinforcement Learning agent, and I ran into some reproducibility problems while testing it on CartPole. This should be one of the simplest tests of an RL agent, and even here I found it took me a while to get repeatable results.
I was trying to follow Andrej Karpathy and Matthew Rahtz‘s recommendations to focus on reproducibility and set up random seeds early, but this was taking me much longer than expected – despite adding seeds everywhere I thought necessary, sometimes my agent would learn a perfect policy in a few hundred episodes, whereas other times it didn’t find a useful policy even after a thousand episodes.
I checked the obvious – setting seeds for PyTorch, NumPy, and the OpenAI gym environment I was using. I even added a seed for Python’s random module, even though I was pretty sure I didn’t use that anywhere.
RANDOM_SEED = 0
torch.manual_seed(RANDOM_SEED)
env.seed(RANDOM_SEED)
np.random.seed(RANDOM_SEED)
random.seed(RANDOM_SEED)Still I got different results on each run. I found a few resources pointing me to other things to check:
- Consistency in data preparation and processing (not really relevant here- all the data I’m processing comes from the gym environment)
- CuDNN specific seeding in PyTorch (my network is small enough to run quickly on CPU, so I’m not using CuDNN)
Out of ideas, I returned to debugging. My initial policy and target network weights were the same each run. Good. The first environment observation was the same too. Also good. But then, when I came to selecting a random action, I noticed env.action_space.sample() sometimes gave different results. Bad.
I looked through the OpenAI gym code for random seeds, and couldn’t find any seeding being done on the action space, even when the environment is passed a specific seed! I then found this commit, where Greg Brockman and others discuss how seeding should be done in OpenAI Gym environments. It looks like they initially wanted to seed action spaces as well as environments, but decided not to because they see action space sampling as belonging to the agent rather than the environment.
So here’s the solution, in one extra line:
env.action_space.seed(RANDOM_SEED)I’d love to know why this isn’t called from env.seed()!
Anyway, now I’m getting reproducible results. To get an idea of how significant the difference is between different seeds even on a problem as simple of CartPole, here are five runs with different seeds:
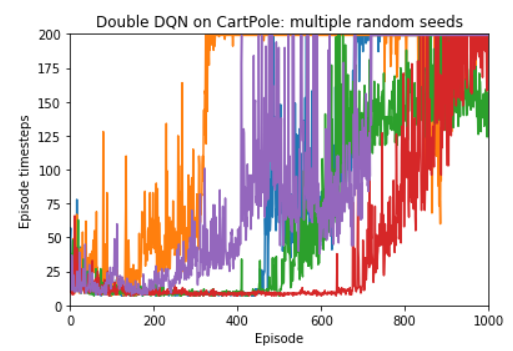
Some resources with other useful reproducibility suggestions:
