Today was NeurIPS Expo, the zeroth day of this year’s Neural Information Processing Systems conference in Montréal. The Expo is a day with content from industry right before the rest of the conference. Below are some highlights from a few of the sessions I managed to attend.
The Montréal Declaration
An initiative of the University of Montréal, the Declaration “aims to spark public debate and encourage a progressive and inclusive orientation to the development of AI”.
Unlike the Asilomar AI Principles, which were set by experts in the field, the principles of the Montréal Declaration are being set by consultation with the public and take a local (Québec-centric) view rather than trying to solve global issues.
Notably, the Declaration will remain open for revision to account for the fact that societal norms and our understanding of AI will adapt. The next draft of the Declaration, with updated principles, will be published on the 4th of December. [now published: English/French]
Despite an attempt to take opinions from a broad cross-section of the population, there was a significant skew towards highly educated people in the ~500 participant group, as well as towards those working in tech, and towards men.
While the content was interesting, the talk was a little unfocused – very little time was spent on context/setup (whose initiative is this? why?) and a lot of time on niche issues/tangents (what preferences might people subscribing to various moral frameworks express about certain trolley problem scenarios?).
One of the speakers suggested that rather than spending time considering moral dilemmas, more time should be spent planning societal/structural changes that would remove or reduce the need for machines to face those dilemmas.
More concretely, rather than optimising for thousands of different trolley problems, we could figure out ways to arrange our roads so that autonomous vehicles are significantly less likely to come across any pedestrians or unexpected objects. We could do this by, for example, investing more in pedestrian infrastructure (e.g. segregated sidewalks and raised crossing points), and rolling out autonomous vehicles only in areas with sufficient such infrastructure.
NetEase FUXI – Reinforcement Learning in Industry
Despite a lot of mentions of ‘AI’ and ‘Big Data’ in the first few minutes of this session, it actually turned out to be fairly interesting.
I didn’t manage to stay long due to a clash with the HRT talk, but here are some interesting points from the first and second parts of the workshop:
- Game companies don’t want their bots to be too good, because humans want to have a chance of winning! So the problem here is different from e.g. DeepMind’s Atari bots. (not that there’s too much danger of unintentionally creating excessively strong strategies with today’s techniques)
- FUXI are trying to create a meta chatbot design engine that can work across games, and a high-level character personality design engine.
- Interesting quote: “Our ultimate goal is to build a virtual human.”
- They framed supervised learning as being about ‘predictions’, and reinforcement learning as being about ‘decisions’, and claimed that recommendation tasks can be better framed in an RL context.
- There was some discussion of RL issues with sample efficiency and exploration leading to limited current real-world use cases (with references to RL never worked and Deep RL Doesn’t Work Yet)
- “Humans are not believed to be very easily simulated” (!)
- Dogs are better at reinforcement learning than DQN (though maybe not as good at Atari games)
- When building ‘customer simulators’ to train RL-based recommendation engines, they found value in trying to simulate intention rather than behaviour (through techniques like Inverse RL and GAIL)
- They’re planning on releasing “VirtualTaobao” simulators, essentially gym environments for recommendation engines.
Hudson River Trading
Everyone attending this panel in the hope of learning the secret Deep Learning techniques that could make them millions in trading was immediately disappointed by the introduction – “Due to the competitive nature of our business we can only talk about problems, not solutions…”
Fortunately for those who stayed anyway, the speakers were all great and the content was interesting.
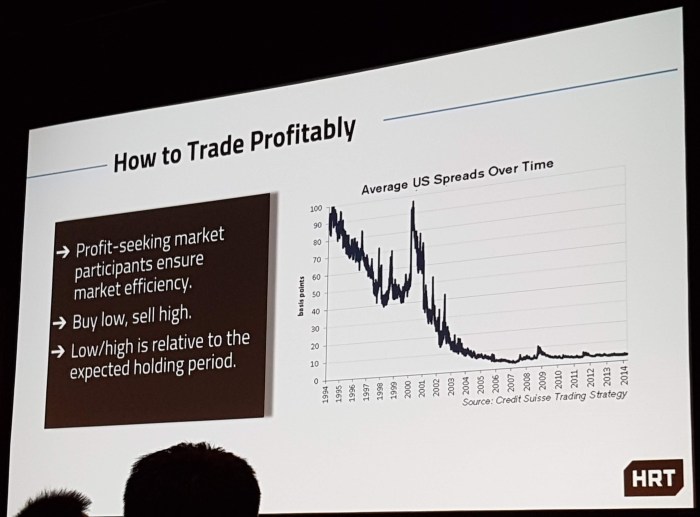
As would be expected for a prop trading firm, most of the Q&As were fairly uninformative though at least slightly amusing.
Audience member 1: “What types of models do you use?”
HRT employee: “We use a variety of different models.”
Audience member 2: “What is your average holding period?”
HRT employee: “Our strategies have a variety of different holding periods.”
Audience member 3: “Are you actually using Deep RL in production trading?”
HRT employee: “I’m afraid I can’t answer that. Come work for us and you’ll find out. ”
Audience member 4: “What are the annual returns and Sharpe ratios for your RL-based strategies? ”
HRT employee: “I cannot answer that question.”
One of the speakers previously worked at DeepMind, and it was interesting to hear him contrast different ‘families’ of RL and which might map most closely to the problem of trading.
The families in his classification were:
- DQN: possibly sample-efficient enough (using Rainbow), but the state space is discrete, and these algorithms are not that great at exploration (though that’s changing). What’s the trading equivalent to a frame in Atari? Is it a tick? Or multiple ticks? How do we set constraints in a way that allows our model to optimise around them?
- AlphaGo: adversarial and with the set of valid actions dependent on the state, but these strategies rely on an accurate world model and require a lot of compute.
- Robotics: continuous N-dimensional actions, similar safety concerns/constraints, shared difficulty of translating model from simulator to reality. Maybe a trading algo dealing with market changes is analogous to robotics algo being robust with respect to lighting changes.
- “Modern Games” (Dota, StarCraft, Capture The Flag): adversarial, simulations are expensive, big networks are required, some of the inputs are “a narrow window into a wider world”. (in the sense that they capture the current state perfectly but don’t tell you about the longer term consequences of your actions)
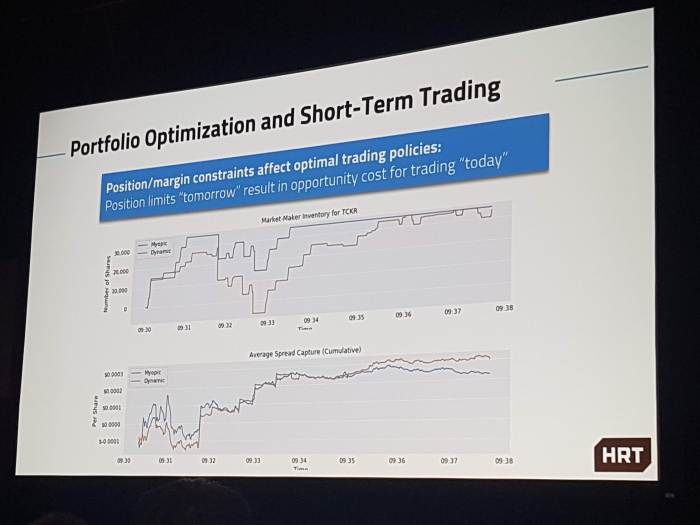
One audience question which did get a meaningful answer was whether they were using RL for portfolio optimisation. The response was that RL isn’t data efficient enough yet for it to be used for multi-day portfolio optimisation, since “the number of days that have happened since the start of electronic trading is not that many”.
Intel – nGraph
Some of this talk went comfortably over my head, but I was pleased to find that I understood more than I expected to.
My understanding is that Intel’s nGraph library is a software optimisation component which sits between different machine learning libraries used to construct computational graphs (TensorFlow, PyTorch, Chainer, PaddlePaddle, MXNet, …) and kernel libraries used to run those graphs on specific hardware (cuDNN MKL-DNN, …).
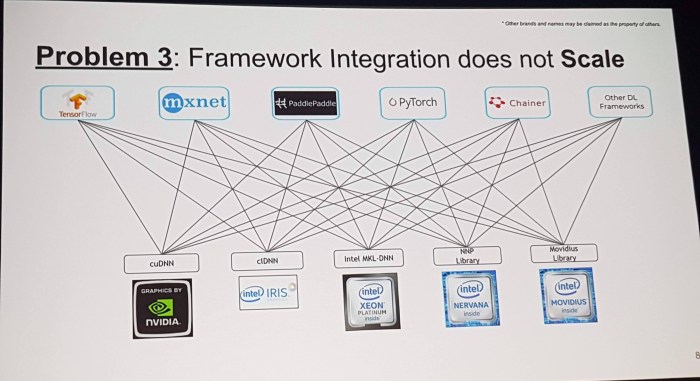
Having one shared library sitting between between these two means that you need to consider m+n different integrations rather than mn integrations. (where m is the number of ML libraries, and n the number of kernel libraries)
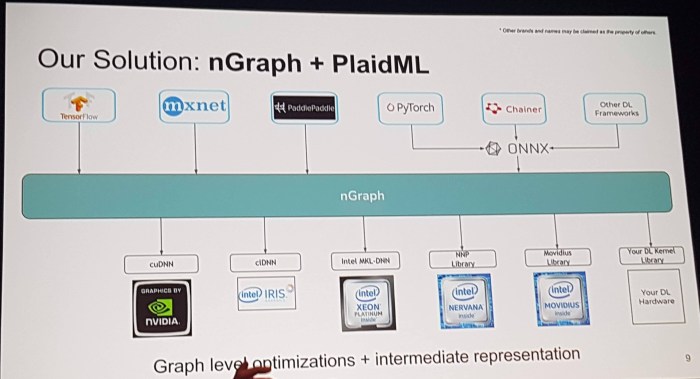
I didn’t understand much of the second part of the talk, but the optimisation examples they gave in the first part of the talk were based around removing redundant or inefficient operations – for example, two consecutive transpose operations (which would cancel each other out) would just be removed. Similarly, if two parts of a graph are doing exactly the same thing they could be condense into one. Adding or multiplying a tensor by zero can be dealt with at compile time.

All this (and much more that I didn’t understand) can supposedly lead to significant performance improvements in training neural nets, particularly for lower batch sizes.
Next: Day 1.

This is very helpful. Looking forward to your notes from other sessions.