Last month I spent a few days, together with some friends, trying to get an entry together for the Pommerman competition at this year’s NeurIPS.
While we learnt a huge amount, we didn’t manage to get an entry together in time for the conference.
All of us were pretty new to reinforcement learning, so maybe it’s not hugely surprising that we didn’t succeed. Still, I think if we’d done things differently we may have got there in time.
Some things we managed to achieve:
Get the game running, and set up some basic reinforcement learning agents (specifically, DQN and PPO) that could play the game.
Set up a training environment on a cloud server, to which we could deploy any number of training configs and have them run 16 at a time.
Set up Tensorboard logging for rewards, wins, and various intermediate metrics (% frequency for each action, # of survivors in each game, etc)
Train hundreds of PPO and DQN agents with different hyperparameters and network architectures.
Set up a validation environment that outputs performance stats for trained agents acting deterministically.
Experiment with experience replay, different types of exploration, CNNs, dropout, and simplified features.
Create different reward models intended to guide the agent to various strategies.
Despite all this, we didn’t manage to train an agent which figured out how to bomb through walls and find opponents. Our most successful agents would (mostly) avoid bombs near them, but otherwise be static.
What mistakes did we make?
We underestimated the difficulty of the problem. We figured we could just set some stock algorithms running on the environment and they’d figure out a basic strategy which we could then iterate on, but this wasn’t the case.
We committed fairly early on to a library (TensorForce) that we hadn’t used before without checking how good it was, or how easy it would be to change things. So when we realised, more than halfway into the project, that we really needed to get our agents to explore more, it was really hard for us to try to debug exploration and implement new techniques.
We spent a lot of time setting up a cloud GPU environment, which we ended up not needing! The networks we were training were so small that it was faster to just run parallel CPU threads.
We didn’t try to reduce complexity or stochasticity early enough, so we didn’t really know why our agents weren’t learning
We (I) introduced a few very frustrating bugs! The highlight was a bug where I featurised the board for our agent, and accidentally changed the board array that all agents (and the display engine) shared. This bug manifested itself as our agent’s icon suddenly changing, and took me hours to debug.
Knowing what we know now, how would we have approached this problem?
Simplify the environment – start with a smaller version of the problem (e.g. 4×4 static grid, one other agent) with deterministic rules. If we can’t learn this then there’s probably no point continuing!
Simplify the agent to the extent where we fully understand everything that’s happening – for example, write a basic DQN agent from scratch. This would’ve made it easier to add different exploration strategies.
Gradually increase complexity, by increasing the grid size or stochasticity.
Add unit tests!
Despite our lack of success, we all learnt a lot and we’ll hopefully be back for another competition!
Some brief notes from day 3 of NeurIPS 2018. Previous notes here: ExpoTutorialsDay 2.
Reproducible, Reusable, and Robust Reinforcement Learning (Professor Joelle Pineau)
I was sad to miss this talk, but lots of people told me it was great so I’ve bookmarked it to watch later.
Investigations into the Human-AI Trust Phenomenon (Professor Ayanna Howard)
A few interesting points in this talk:
Children are unpredictable, and working with data generated from experiments with children can be hard. (for example, children will often try to win at games in unexpected ways)
Automated vision isn’t perfect, but in many cases it’s better than the existing baseline (having a human record certain measurements) and can be very useful.
Having robots show sadness or disappointment turns out to be much more effective than anger for changing a child’s behaviour.
Humans seem to inherently trust robots!
Two cool experiments:
To what extent would people trust a robot in a high-stakes emergency situation?
A research subject is led into a room by a robot, for a yet-to-be-defined experiment. The room fills with smoke, and the subject goes to leave the building. On the way out, the same robot is indicating a direction. Will the subject follow the robot?
It turns out that, yes, almost all of the time, the subject follows the robot.
What about if the robot, when initially leading the subject to the room, makes a mistake and has to be corrected by another human?
Again, surprisingly, the subject still follows the robot in the emergency situation that follows.
The point at which this stopped being true was when they had the robot point to obviously wrong directions (e.g. asking the subject to climb over some furniture).
This research has some interesting conclusions, but I’m not completely convinced. For one, based on the videos of the ’emergency situation’, it seems unlikely that any of the subjects would have believed the emergency situation to be genuine. The smoke is extremely localised, and the ‘exit’ just leads into another room. It seems far more likely to me that the subjects were trying to infer the researchers’ intentions for the study and decided to follow the robot since that was probably what they were meant to do.
Unfortunately this turns out to be because their ethics committee wouldn’t give them approval to run a more realistic version of the study in a separate building, which is a real shame. More on this study in the the paper, or in this longer write-up.
Does racism and sexism apply to people’s perception of robots?
Say we program a robot to perform a certain sequence of behaviours, and then ask someone to interpret the robot’s intention behind that behaviour. Will their interpretation be affected by a robot’s ‘race’ or ‘gender’?
It turns out that, yes, it is. For example, when primed to be aware of the ‘race’ of a robot, subjects are more likely to interpret the behaviour as angry when the robot is black than when the robot is white.
But when humans are not primed to pay attention to race (and just shown robots with different colours), the effect disappears. Paper here.
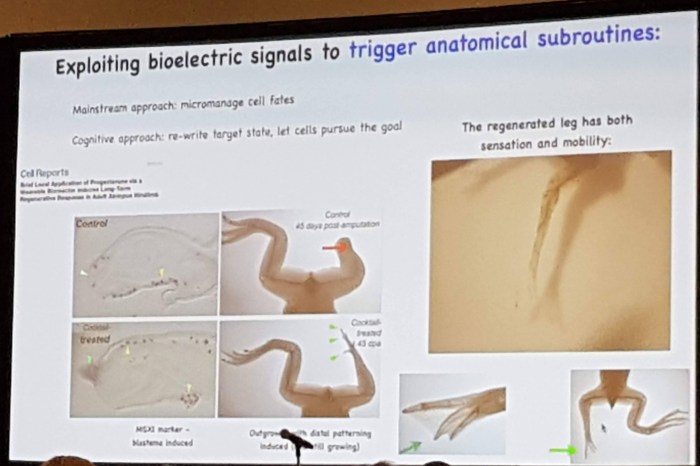
Just a brief highlight from day two: Professor Michael Levin’s incredible talk on What Bodies Think About, summarising 15 years of research in exploring the hardware/software distinction in biology. Hello, Cronenberg World.
A brief introduction on how the brain is far from the only place where computation happens in biology. Experiments with regenerative flatworms show that memories persist even when their heads are removed and grow back. Butterflies can remember experiences they had when they were caterpillars.
Then the key bit of the talk: reverse engineering bioelectric signals to trigger high-level anatomical subroutines – aka “reprogramming organs”. For example, telling a normal frog to “regrow a leg”, or convincing a flatworm to grow a different shape head that belongs to a much older species of flatworm. No genomic editing or stem cells – but controlling bioelectric signals by changing ion channels directly or through drugs.
The ultimate goal: a biological compiler. This could lead to amazing new regenerative medicine, though there are clearly a lot of ethical issues that need to be thought through!
Do watch the full talk when you get a chance. It’s the only talk I ever remember attending where my jaw literally dropped, several times.
Monday was the first day of the core conference, following the Expo on Sunday. There were a number of really interesting tutorials. Here’s a brief summary of the three I managed to attend.
Scalable Bayesian Inference (Professor David Dunson)
This tutorial explored one main question: how do we go beyond point estimates to robust uncertainty quantification when we have lots of samples (i.e. ‘n’ is large) or lots of dimensions (i.e. ‘p’ is large)?
The introduction was Professor Dunson’s personal ode to Markov Chain Monte Carlo (MCMC) methods, and in particular the Metropolis-Hastings algorithm. In his words, “Metropolis-Hastings is one of the most beautiful algorithms ever devised”.
He tackled some of the reasons for the (in his view incorrect) belief that MCMC doesn’t scale, and showed how MCMC methods can now be used to perform bayesian inference even on very large data sets. Some key approaches involve clever parallelisation (WASP/PIE) and approximating transition kernels (aMCMC). Interestingly, some of these techniques have the combined advantage of improving computational efficiency and mixing (an analogue of exploration in bayesian inference).
A recurring theme throughout the talk was Professor Dunson’s call for more people to work in the field of uncertainty quantification: “There are open problems and a huge potential for new research”.
His recent work on coarsening in bayesian inference – a specific way of regularising the posterior – allows inference to be more robust to noise and helps manage the bias/variance trade-off when optimising for interpretability (i.e. if a relatively simple model is only slightly worse than a very complex model, we probably want to go with the simple model). This is useful for example in medicine, where doctors want to be able to understand and critique predictions rather than using black-box point estimates.
The second part of the talk went on to explore high-dimensional data sets, particularly those with small sample size: “you’ve given us a billion predictors and you’ve run this study on ten mice.”
Naive approaches in this area can have serious issues with multiple hypothesis testing or requiring an unjustifiably strong prior to get a reasonable uncertainty estimate. Point estimates can be even worse – or, in Professor Dunson’s words, “scientifically dangerous”. Accurate uncertainty quantification can allow us to say “We don’t have enough information to answer these questions.”
The hope is that over time, we can extend these methods to help scientists by saying “No, we can’t answer <this specific question that you’ve asked>. But given the data we have, <here’s something else we can do>. ”
Unsupervised Deep Learning (Alex Graves from DeepMind, Marc’Aurelio Ranzato from Facebook)
This talk started with a reclassification of ML techniques: rather than thinking of three categories (supervised learning/unsupervised learning/reinforcement learning), it can be more useful to think of four categories across two dimensions.
This talk focused on the two quadrants on the right.
The key idea I took from this talk was that we can apply unsupervised learning to problems we’ve previously thought of as supervised learning, if we’re smart about how we do it.
For example, the classic approach to machine translation is to take a large set of sentence pairs across two languages, and then train a neural net to learn the mapping between the two. While this can work well, it relies on a lot of labelled data, which isn’t always available. Since there’s far more single-language data available, another approach would be to get a model to learn the structure of the data, for example by embedding words or phrases in some space which can capture relationships between them.
Since languages correspond to things in the real world, if we can learn an accurate enough mapping for two separate languages we can then find a way to go between languages by exploiting the shared word embedding space. Doing this for phrases or sentences is harder, but can already improve on supervised learning in certain special cases – for example in English-Urdu,
The available English-Urdu labelled data is restricted to very specific specific domains (genomics data/subtitles), and doesn’t allow supervised models to generalise well to other domains. In this case unsupervised models trained on monolingual examples can do abetter job (albeit still not necessarily good enough to be useful in practice).
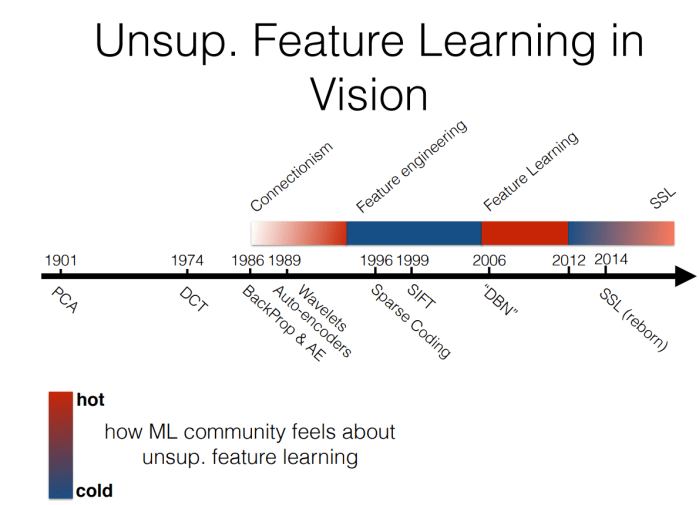
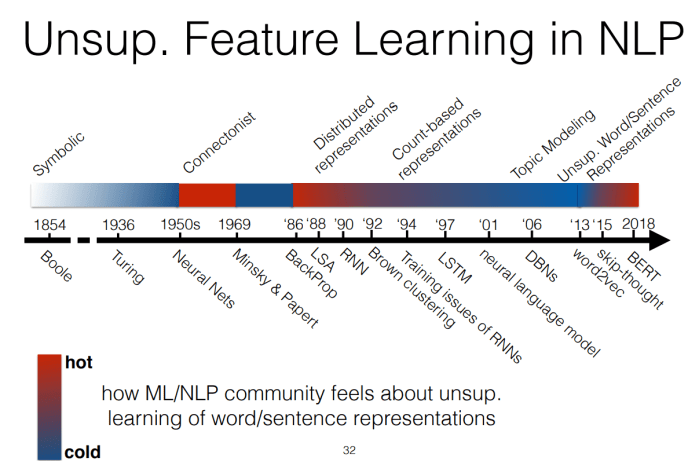
Also interesting were the timelines of popularity of unsupervised feature learning in vision and natural language processing, showing how this type of approach goes in and out of fashion over time.
Both speakers here were quite optimistic about how much content they’d get through in an hour, so they didn’t quite manage to cover everything. I’d highly recommend checking out the slides though, since there are lots of references to interesting papers: part 1 and part 2.
Counterfactual Inference (Professor Susan Athey)
Like a few others I spoke to, I had high hopes for this talk but was a little disappointed. A lot of time was spent covering basic stats concepts with text-heavy slides, and even though Professor Athey’s quite an engaging speaker I didn’t feel like I learnt very much or even gained a good intuition for the types of problems her framework of counterfactual inference can solve.
It felt like much of the work was a slight reframing of supervised learning to account for unobserved counterfactuals where the probability of observation (propensity score) is correlated with some of the underlying covariates.
Having said that, it was nice to get a different perspective from someone who’s working in economics where the standards for publication and expectations of interpretability can be very different. Some of the notation was also interesting and new to me, and might be useful to anyone wanting to do a better job of considering counterfactuals in their work. It was noticeable that she compared her work to Deep Learning/AlphaGo quite a few times, even though it felt like her tools for counterfactual inference operate in quite a different problem domain. In the vain of Marc’Aurelio Ranzato’s popularity charts from above, I wonder if there’s an expectation that people would find the work more interesting if framed in terms of today’s Deep Learning, which would be a shame.
Some of the themes from the Scalable Bayesian Inference workshop came up again, such as the idea that modern ML techniques haven’t been used much in economics since it’s hard to get things like confidence intervals. Towards the end Professor Athey presented some recent contributions to the field, such as Generalised Random Forests.
For anyone interested in learning more about the intersection of machine learning and econometrics, AEA has a longer lecture series featuring Professor Athey which goes into much more depth on the topic.
Today was NeurIPS Expo, the zeroth day of this year’s Neural Information Processing Systems conference in Montréal. The Expo is a day with content from industry right before the rest of the conference. Below are some highlights from a few of the sessions I managed to attend.
The Montréal Declaration
An initiative of the University of Montréal, the Declaration “aims to spark public debate and encourage a progressive and inclusive orientation to the development of AI”.
Unlike the Asilomar AI Principles, which were set by experts in the field, the principles of the Montréal Declaration are being set by consultation with the public and take a local (Québec-centric) view rather than trying to solve global issues.
Notably, the Declaration will remain open for revision to account for the fact that societal norms and our understanding of AI will adapt. The next draft of the Declaration, with updated principles, will be published on the 4th of December. [now published: English/French]
Despite an attempt to take opinions from a broad cross-section of the population, there was a significant skew towards highly educated people in the ~500 participant group, as well as towards those working in tech, and towards men.
While the content was interesting, the talk was a little unfocused – very little time was spent on context/setup (whose initiative is this? why?) and a lot of time on niche issues/tangents (what preferences might people subscribing to various moral frameworks express about certain trolley problem scenarios?).
One of the speakers suggested that rather than spending time considering moral dilemmas, more time should be spent planning societal/structural changes that would remove or reduce the need for machines to face those dilemmas.
More concretely, rather than optimising for thousands of different trolley problems, we could figure out ways to arrange our roads so that autonomous vehicles are significantly less likely to come across any pedestrians or unexpected objects. We could do this by, for example, investing more in pedestrian infrastructure (e.g. segregated sidewalks and raised crossing points), and rolling out autonomous vehicles only in areas with sufficient such infrastructure.
NetEase FUXI – Reinforcement Learning in Industry
Despite a lot of mentions of ‘AI’ and ‘Big Data’ in the first few minutes of this session, it actually turned out to be fairly interesting.
I didn’t manage to stay long due to a clash with the HRT talk, but here are some interesting points from the first and second parts of the workshop:
Game companies don’t want their bots to be too good, because humans want to have a chance of winning! So the problem here is different from e.g. DeepMind’s Atari bots. (not that there’s too much danger of unintentionally creating excessively strong strategies with today’s techniques)
FUXI are trying to create a meta chatbot design engine that can work across games, and a high-level character personality design engine.
Interesting quote: “Our ultimate goal is to build a virtual human.”
They framed supervised learning as being about ‘predictions’, and reinforcement learning as being about ‘decisions’, and claimed that recommendation tasks can be better framed in an RL context.
There was some discussion of RL issues with sample efficiency and exploration leading to limited current real-world use cases (with references to RL never worked and Deep RL Doesn’t Work Yet)
“Humans are not believed to be very easily simulated” (!)
Dogs are better at reinforcement learning than DQN (though maybe not as good at Atari games)
When building ‘customer simulators’ to train RL-based recommendation engines, they found value in trying to simulate intention rather than behaviour (through techniques like Inverse RL and GAIL)
They’re planning on releasing “VirtualTaobao” simulators, essentially gym environments for recommendation engines.
Hudson River Trading
Everyone attending this panel in the hope of learning the secret Deep Learning techniques that could make them millions in trading was immediately disappointed by the introduction – “Due to the competitive nature of our business we can only talk about problems, not solutions…”
Fortunately for those who stayed anyway, the speakers were all great and the content was interesting.
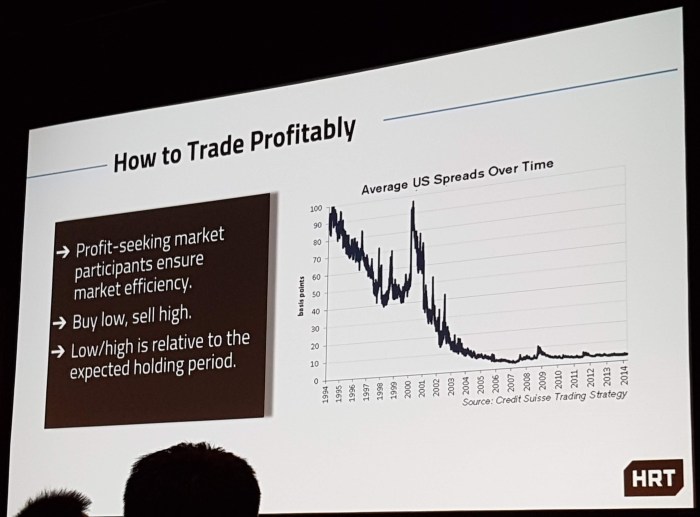
HRT spent some time at the beginning of their talk framing their firm (and prop trading firms more generally) as beneficial to society by showing a reduction in US equity spreads over the past few decades, and linking this to lower trading costs for investors.
As would be expected for a prop trading firm, most of the Q&As were fairly uninformative though at least slightly amusing. Audience member 1: “What types of models do you use?” HRT employee: “We use a variety of different models.” Audience member 2: “What is your average holding period?” HRT employee: “Our strategies have a variety of different holding periods.” Audience member 3: “Are you actually using Deep RL in production trading?” HRT employee: “I’m afraid I can’t answer that. Come work for us and you’ll find out. ” Audience member 4: “What are the annual returns and Sharpe ratios for your RL-based strategies? ” HRT employee: “I cannot answer that question.”
One of the speakers previously worked at DeepMind, and it was interesting to hear him contrast different ‘families’ of RL and which might map most closely to the problem of trading.
The families in his classification were:
DQN: possibly sample-efficient enough (using Rainbow), but the state space is discrete, and these algorithms are not that great at exploration (though that’s changing). What’s the trading equivalent to a frame in Atari? Is it a tick? Or multiple ticks? How do we set constraints in a way that allows our model to optimise around them?
AlphaGo: adversarial and with the set of valid actions dependent on the state, but these strategies rely on an accurate world model and require a lot of compute.
Robotics: continuous N-dimensional actions, similar safety concerns/constraints, shared difficulty of translating model from simulator to reality. Maybe a trading algo dealing with market changes is analogous to robotics algo being robust with respect to lighting changes.
“Modern Games” (Dota, StarCraft, Capture The Flag): adversarial, simulations are expensive, big networks are required, some of the inputs are “a narrow window into a wider world”. (in the sense that they capture the current state perfectly but don’t tell you about the longer term consequences of your actions)
One audience question which did get a meaningful answer was whether they were using RL for portfolio optimisation. The response was that RL isn’t data efficient enough yet for it to be used for multi-day portfolio optimisation, since “the number of days that have happened since the start of electronic trading is not that many”.
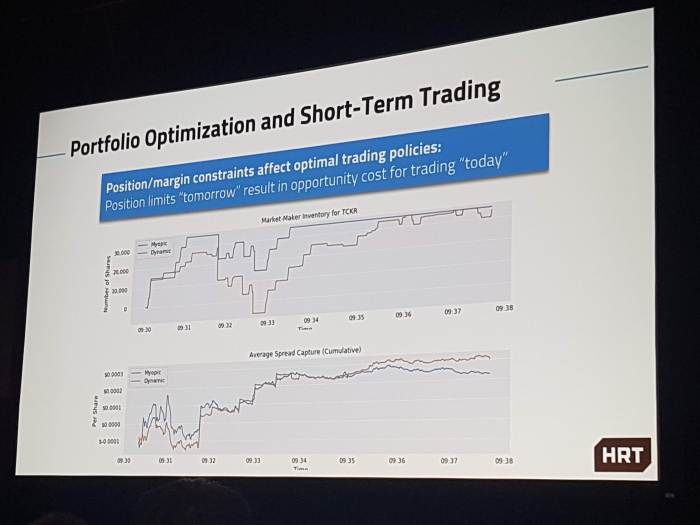
A slide from the portfolio optimisation part of the talk, showing how optimising around position/margin constraints can be preferable to the naive myopic strategy of trading as you normally would until you hit the constraints.
Intel – nGraph
Some of this talk went comfortably over my head, but I was pleased to find that I understood more than I expected to.
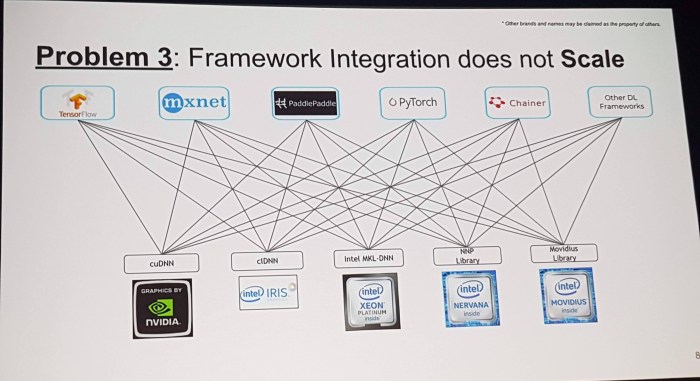
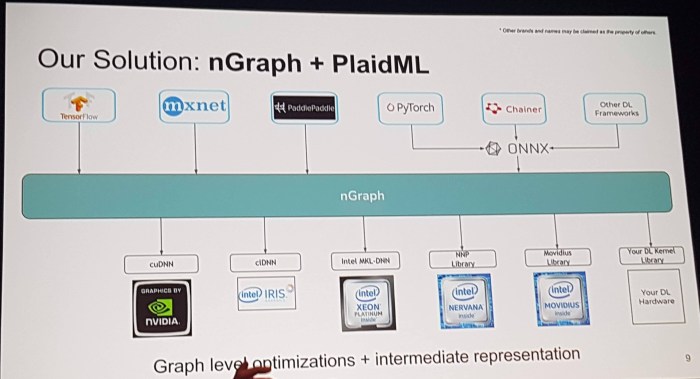
My understanding is that Intel’s nGraph library is a software optimisation component which sits between different machine learning libraries used to construct computational graphs (TensorFlow, PyTorch, Chainer, PaddlePaddle, MXNet, …) and kernel libraries used to run those graphs on specific hardware (cuDNN MKL-DNN, …).
Having one shared library sitting between between these two means that you need to consider m+n different integrations rather than mn integrations. (where m is the number of ML libraries, and n the number of kernel libraries)
I didn’t understand much of the second part of the talk, but the optimisation examples they gave in the first part of the talk were based around removing redundant or inefficient operations – for example, two consecutive transpose operations (which would cancel each other out) would just be removed. Similarly, if two parts of a graph are doing exactly the same thing they could be condense into one. Adding or multiplying a tensor by zero can be dealt with at compile time.
All this (and much more that I didn’t understand) can supposedly lead to significant performance improvements in training neural nets, particularly for lower batch sizes.
Planning – the fundamental skill of coming up with a strategy and choosing actions that maximise the probability of winning. The field of reinforcement learning has a wealth of approaches for this.
Cooperation – planning in the presence of other agents with the same goal and possibly known architecture/behaviour.
Opponent modelling – planning in the presence of other agents with opposing goals and unknown behaviour.
Planning/reinforcement learning
Proximal Policy Optimisation (PPO) (2017) is a type of reinforcement learning technique developed by OpenAI that appears to be better at generalising to new tasks than older reinforcement learning techniques, and requires less hyperparameter tuning. (in contrast, techniques like DQN can perform very well once adapted to a problem, but will be useless unless the right hyperparameters are chosen)
Monte Carlo Tree Search (2012) gives an extensive overview of Monte Carlo Tree Search (MCTS) methods in various domains, as well as describing extensions for multi-player scenarios. MCTS is a method for building a reduced decision tree, selectively looking multiple moves ahead before deciding on an action.
Monte Carlo Tree Search and Reinforcement Learning (2017) reviews methods combining MCTS and other reinforcement learning techniques. The biggest success story so far is DeepMind’s AlphaGo, which managed to beat all previous Go playing algorithms as well as the best human players, for the first time ever, by combining MCTS with deep neural networks.
Multi-Agent DDPG is a technique developed by OpenAI, based on the Deep Deterministic Policy Gradient technique, where agents learn a centralised critic based on the observations and actions of all agents. The researchers found this technique to outperform traditional RL algorithms (DQN/DDPG/TRPO) on various multi-agent environments.
Cooperative Multi-Agent Learning (2005) is an overview of multi-agent learning approaches. At the highest level, it distinguishes between team learning (one learning process for the entire team) and concurrent learning (multiple concurrent learning processes).
Machine Theory of Mind (2018) is a recent paper developing a system for learning to model other agents in gridworld environments, by predicting their behaviour through observation.
Pommerman is a four-player game, based on Nintendo’s Bomberman, built for testing autonomous agents.
Together with James and Henry, I’m going to try to build two bots and enter them in the team Bomberman competition, which takes place at the beginning of December.
In a test of multi-agent learning, the two bots will face off against other bots, who they’ll try to blow up with bombs while avoiding being blown up themselves.
Our plan is:
Get the basic Pommerman environment running on our laptops.
Understand how the game and example agents work.
Set up a way to run lots of iterations of competitions between various agents.
Improve the example agents with more advanced heuristics-based play.
Try out some techniques from the multi-agent learning literature, and see if we can systematically beat our heuristics-based agents.
???
Submit our best team of two agents, and compete against other teams live at NIPS 2018.
Progress so far: environment installed. Example agents running. Next up: understand how they work.
Will we manage to build any agents that beat the example agents? Will our agents perform as expected on match day, or crash and freeze in live play? Will we win enough games to make it on to the leaderboard and win one of the prizes? To be continued…