Monday was the first day of the core conference, following the Expo on Sunday. There were a number of really interesting tutorials. Here’s a brief summary of the three I managed to attend.
Scalable Bayesian Inference (Professor David Dunson)
This tutorial explored one main question: how do we go beyond point estimates to robust uncertainty quantification when we have lots of samples (i.e. ‘n’ is large) or lots of dimensions (i.e. ‘p’ is large)?

The introduction was Professor Dunson’s personal ode to Markov Chain Monte Carlo (MCMC) methods, and in particular the Metropolis-Hastings algorithm. In his words, “Metropolis-Hastings is one of the most beautiful algorithms ever devised”.
He tackled some of the reasons for the (in his view incorrect) belief that MCMC doesn’t scale, and showed how MCMC methods can now be used to perform bayesian inference even on very large data sets. Some key approaches involve clever parallelisation (WASP/PIE) and approximating transition kernels (aMCMC). Interestingly, some of these techniques have the combined advantage of improving computational efficiency and mixing (an analogue of exploration in bayesian inference).
A recurring theme throughout the talk was Professor Dunson’s call for more people to work in the field of uncertainty quantification: “There are open problems and a huge potential for new research”.
His recent work on coarsening in bayesian inference – a specific way of regularising the posterior – allows inference to be more robust to noise and helps manage the bias/variance trade-off when optimising for interpretability (i.e. if a relatively simple model is only slightly worse than a very complex model, we probably want to go with the simple model). This is useful for example in medicine, where doctors want to be able to understand and critique predictions rather than using black-box point estimates.

The second part of the talk went on to explore high-dimensional data sets, particularly those with small sample size: “you’ve given us a billion predictors and you’ve run this study on ten mice.”
Naive approaches in this area can have serious issues with multiple hypothesis testing or requiring an unjustifiably strong prior to get a reasonable uncertainty estimate. Point estimates can be even worse – or, in Professor Dunson’s words, “scientifically dangerous”. Accurate uncertainty quantification can allow us to say “We don’t have enough information to answer these questions.”

The hope is that over time, we can extend these methods to help scientists by saying “No, we can’t answer <this specific question that you’ve asked>. But given the data we have, <here’s something else we can do>. ”

Unsupervised Deep Learning (Alex Graves from DeepMind, Marc’Aurelio Ranzato from Facebook)
This talk started with a reclassification of ML techniques: rather than thinking of three categories (supervised learning/unsupervised learning/reinforcement learning), it can be more useful to think of four categories across two dimensions.

The key idea I took from this talk was that we can apply unsupervised learning to problems we’ve previously thought of as supervised learning, if we’re smart about how we do it.
For example, the classic approach to machine translation is to take a large set of sentence pairs across two languages, and then train a neural net to learn the mapping between the two. While this can work well, it relies on a lot of labelled data, which isn’t always available. Since there’s far more single-language data available, another approach would be to get a model to learn the structure of the data, for example by embedding words or phrases in some space which can capture relationships between them.
Since languages correspond to things in the real world, if we can learn an accurate enough mapping for two separate languages we can then find a way to go between languages by exploiting the shared word embedding space. Doing this for phrases or sentences is harder, but can already improve on supervised learning in certain special cases – for example in English-Urdu,

Also interesting were the timelines of popularity of unsupervised feature learning in vision and natural language processing, showing how this type of approach goes in and out of fashion over time.
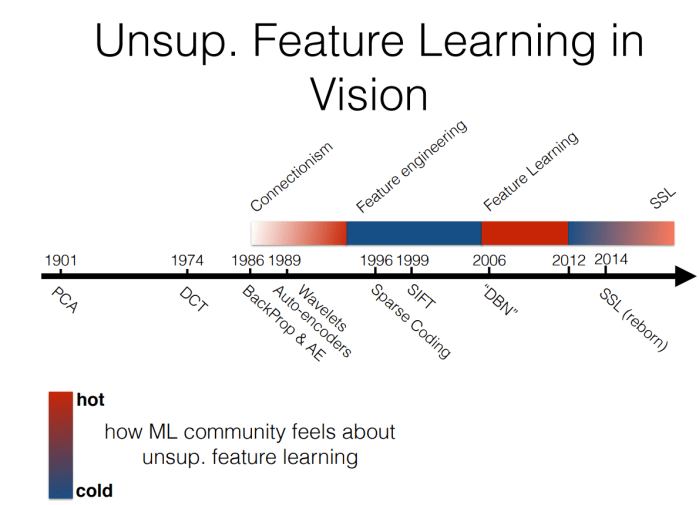
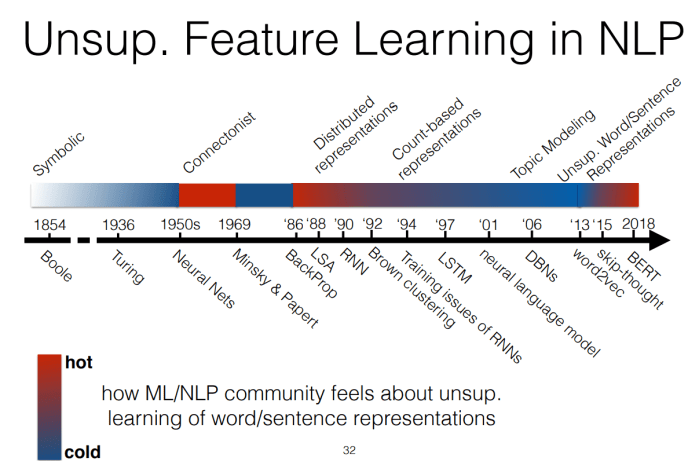
Both speakers here were quite optimistic about how much content they’d get through in an hour, so they didn’t quite manage to cover everything. I’d highly recommend checking out the slides though, since there are lots of references to interesting papers: part 1 and part 2.
Counterfactual Inference (Professor Susan Athey)
Like a few others I spoke to, I had high hopes for this talk but was a little disappointed. A lot of time was spent covering basic stats concepts with text-heavy slides, and even though Professor Athey’s quite an engaging speaker I didn’t feel like I learnt very much or even gained a good intuition for the types of problems her framework of counterfactual inference can solve.
It felt like much of the work was a slight reframing of supervised learning to account for unobserved counterfactuals where the probability of observation (propensity score) is correlated with some of the underlying covariates.
Having said that, it was nice to get a different perspective from someone who’s working in economics where the standards for publication and expectations of interpretability can be very different. Some of the notation was also interesting and new to me, and might be useful to anyone wanting to do a better job of considering counterfactuals in their work. It was noticeable that she compared her work to Deep Learning/AlphaGo quite a few times, even though it felt like her tools for counterfactual inference operate in quite a different problem domain. In the vain of Marc’Aurelio Ranzato’s popularity charts from above, I wonder if there’s an expectation that people would find the work more interesting if framed in terms of today’s Deep Learning, which would be a shame.

Some of the themes from the Scalable Bayesian Inference workshop came up again, such as the idea that modern ML techniques haven’t been used much in economics since it’s hard to get things like confidence intervals. Towards the end Professor Athey presented some recent contributions to the field, such as Generalised Random Forests.
For anyone interested in learning more about the intersection of machine learning and econometrics, AEA has a longer lecture series featuring Professor Athey which goes into much more depth on the topic.
Next: Day 2.

One thought on “NeurIPS Day 1: Tutorials”