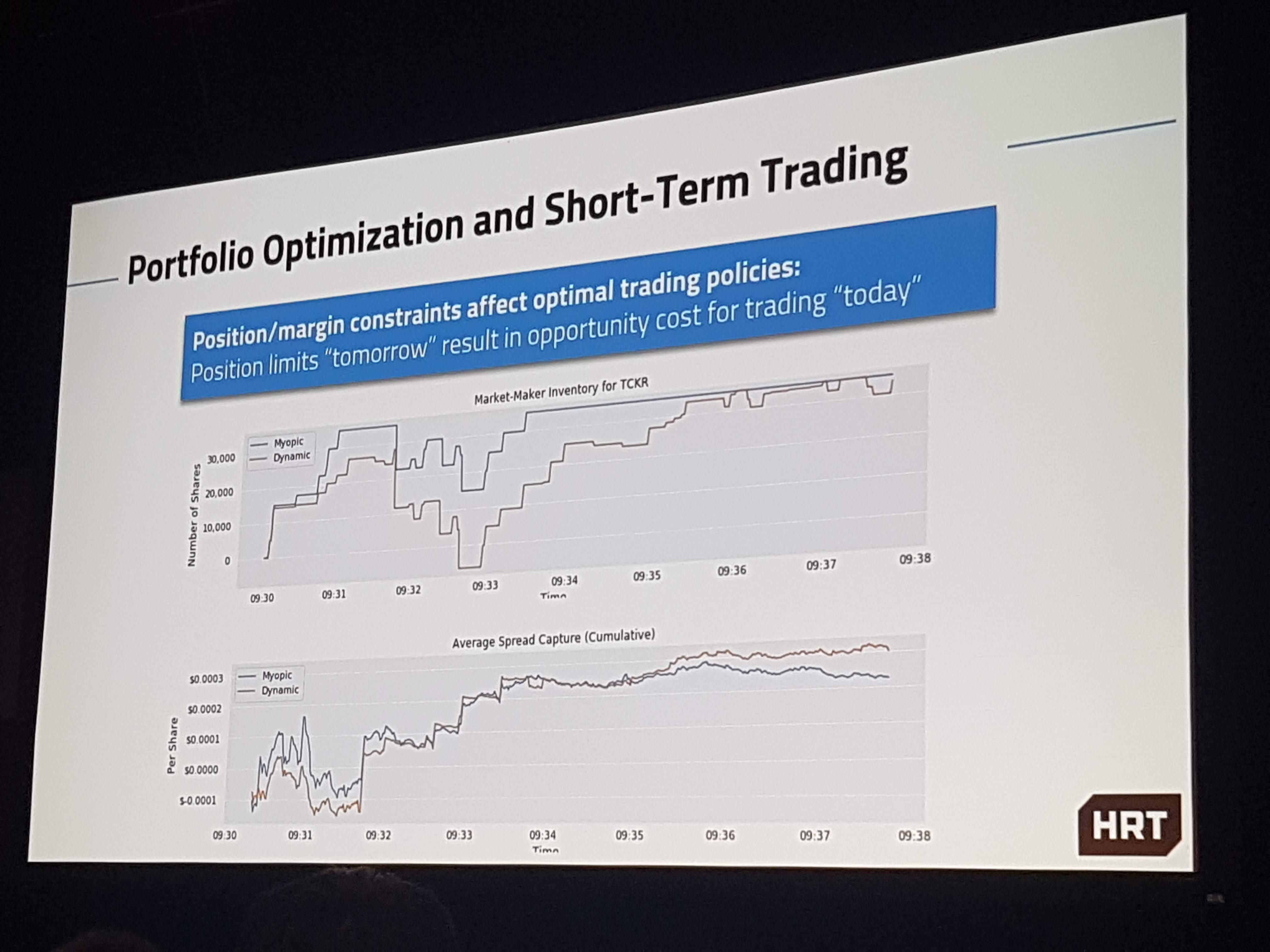
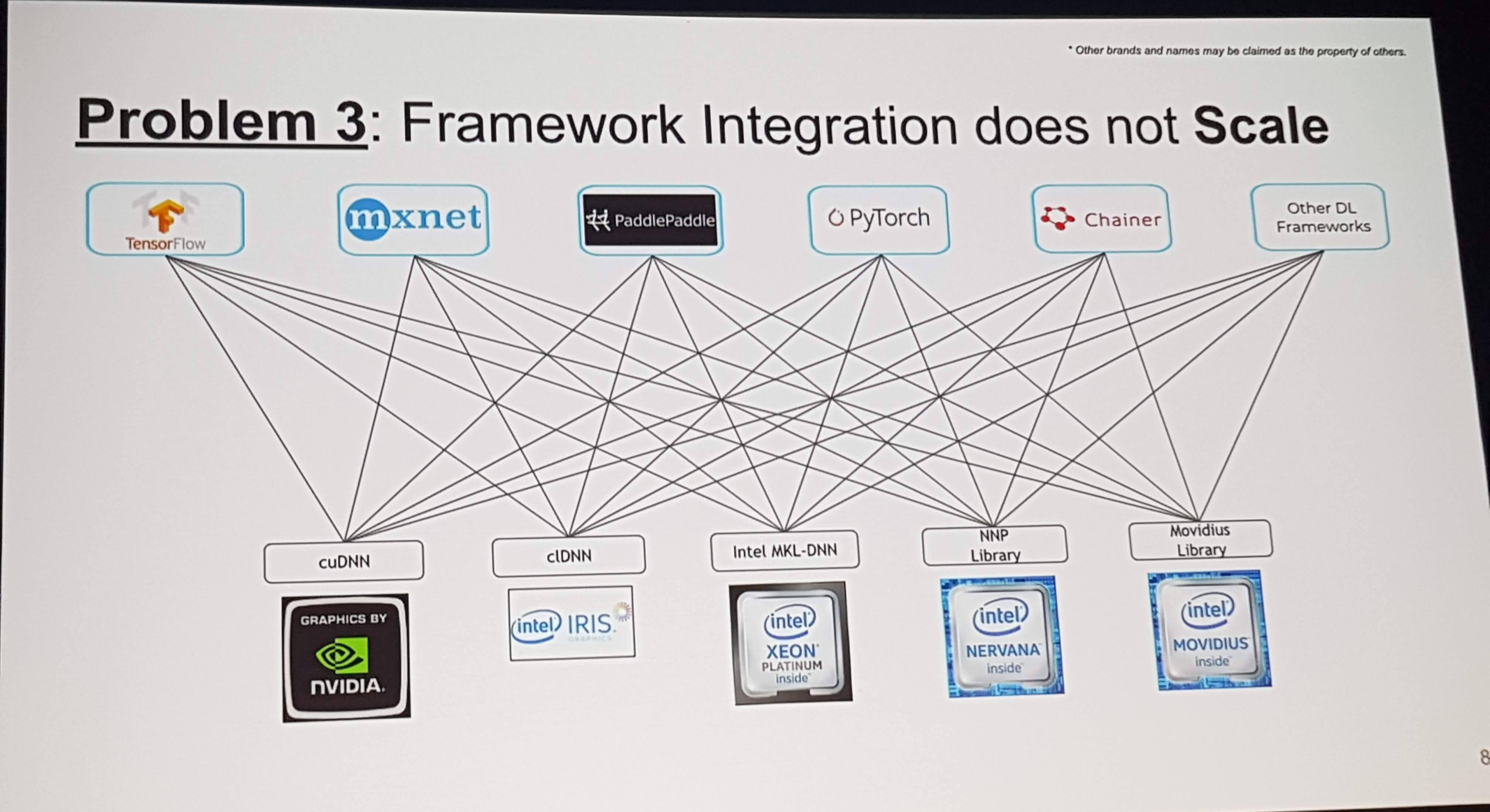
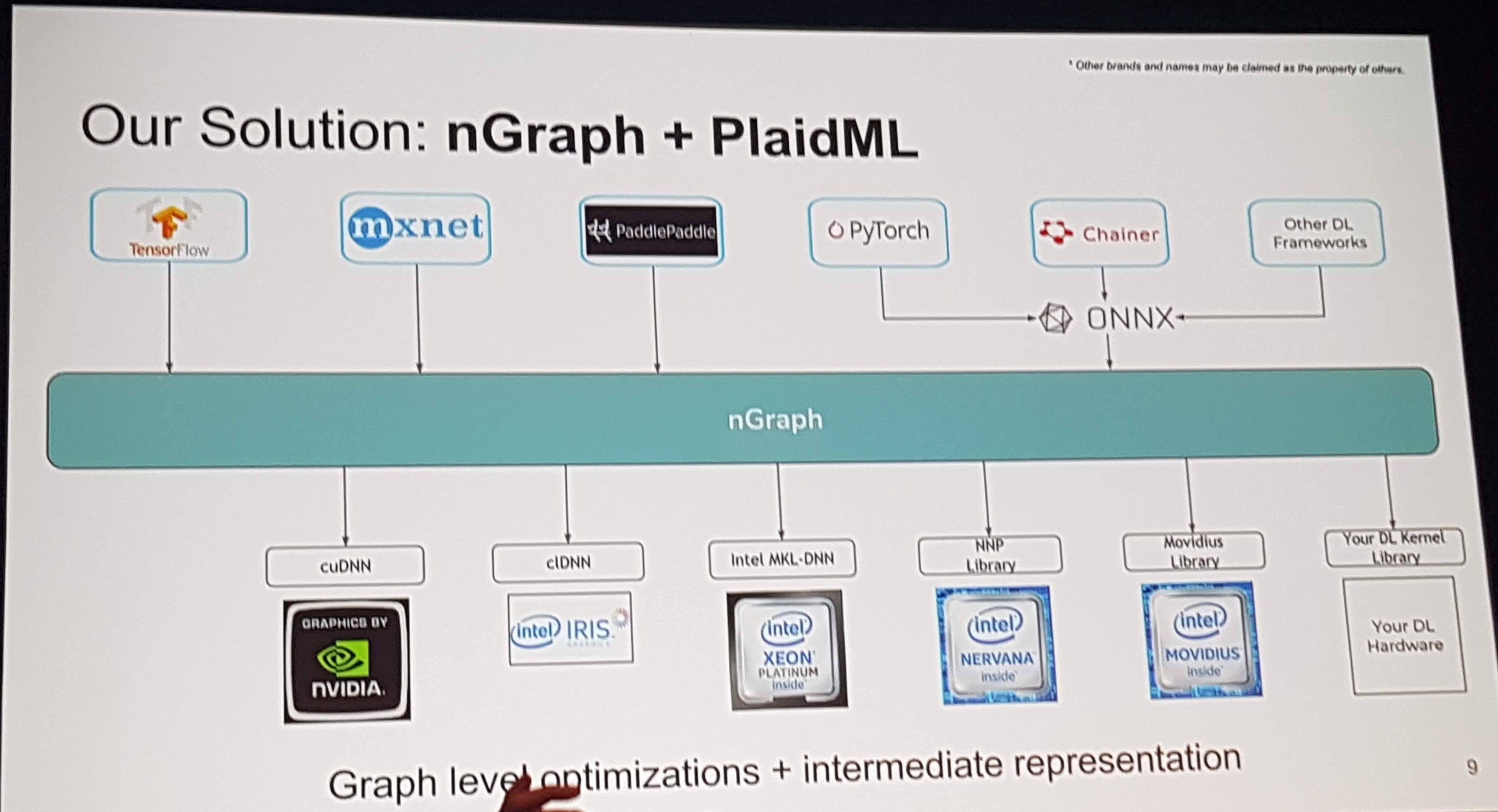
It’s really easy now to create a simple website from scratch!
A few months ago I was looking for a directory of ongoing machine learning competitions (like the kind you get on Kaggle), but I couldn’t find one.
So I decided to build a simple web page that just listed them. I was lucky that the domain mlcontests.com was available and my hosting provider LCN were having a sale on domains, so I got that domain for free for the first year. (their customer service is great and they’re currently doing free .co.uk domains!)
Since I didn’t need anything more fancy than a static page, I went with GitHub Pages for hosting, which is free and fast. The initial version of the page looked like this:
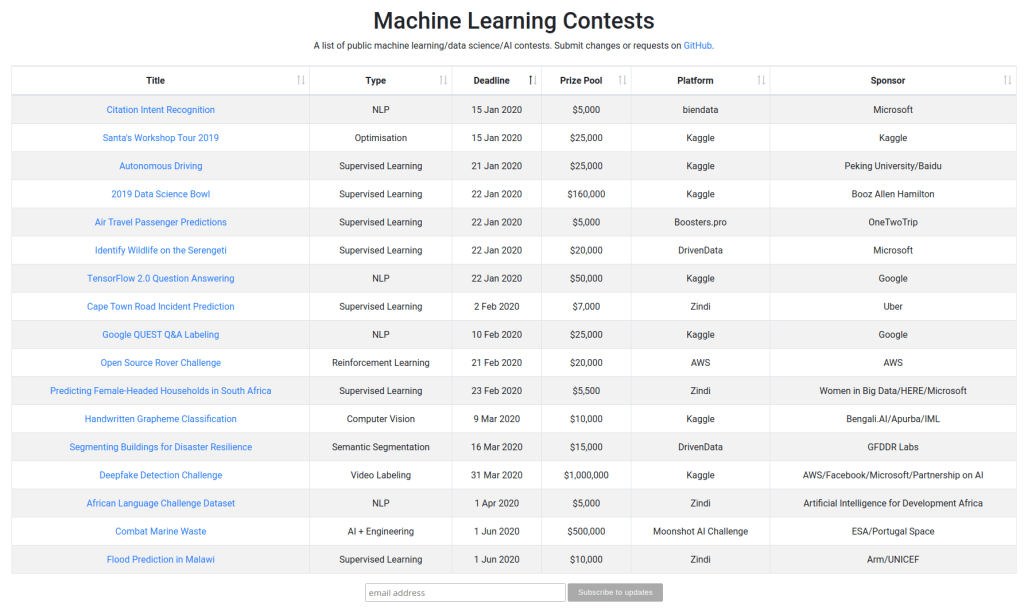
I was tempted to go with a database back-end, but ended up just keeping the list of competitions in a JSON file. This meant anyone could propose changes through pull requests on the project’s GitHub repository, and I was surprised that within a few weeks several people had added competitions I didn’t yet know about!
After I got a few visitors I realised a big grid really didn’t work on mobile, so I spent a bit of time trying to improve that. I hadn’t done any real web development in almost a decade, but with a little help (thanks Natasha!) and a bit of trial and error I got it to be much more usable on mobile.
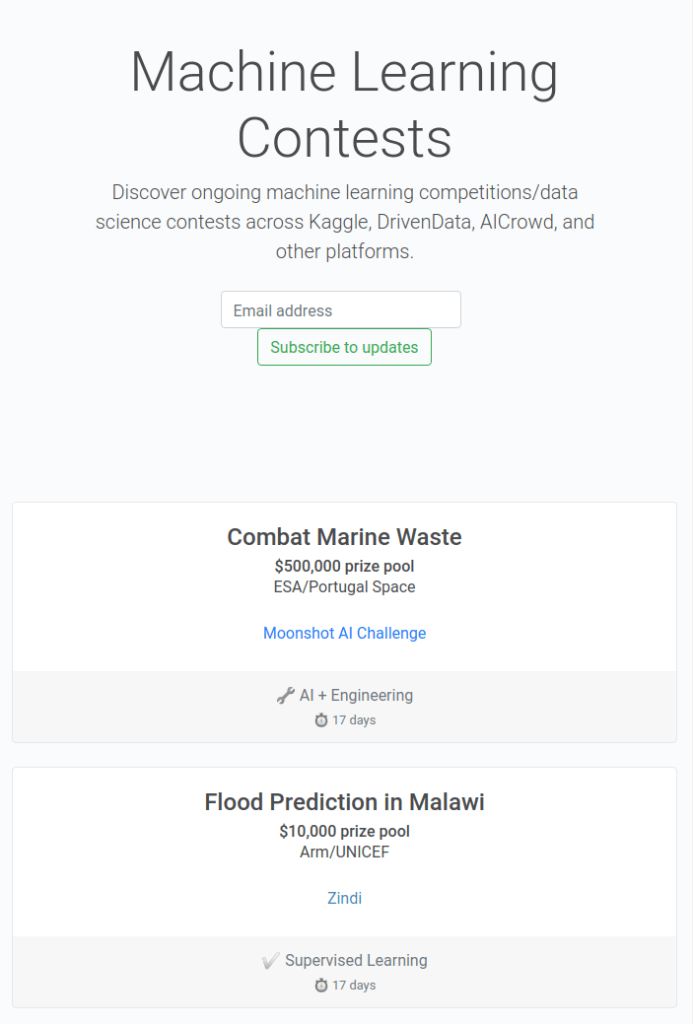
From the start I’d had a form on the page so visitors could join the mailing list. It’s really easy (and free) to set this up through mailchimp, and I feel like it’s worth doing even if you’re not sure you’ll send many emails. So far around 500 people have joined the mailing list, and I’ve sent a handful of updates.
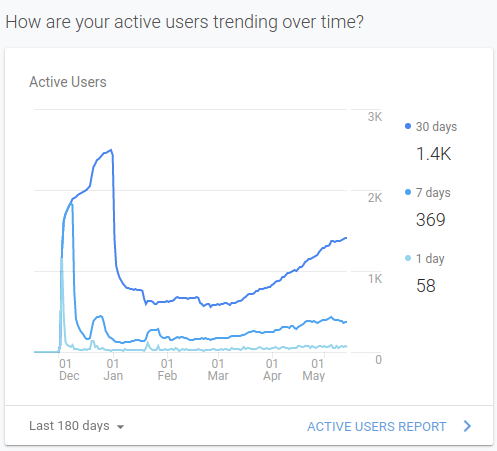
I also added Google Analytics early on, and it’s been nice to see the traffic growth. There was an temporary spike at launch when I posted the site on Reddit and Hacker News, followed by a brief plateau, after which the traffic increase has been slow but steady.
Most of the traffic comes through search, and I’ve found Google Search Console super valuable in trying to see which phrases people are searching for when they end up on my site, and for which phrases I could be ranking higher. It also pointed out a few site usability issues which could have been hurting my ranking.
I used the free Moz Pro trial to figure out which sites I should be trying to get links from in order to rank higher for relevant keywords. This led me to a few Medium posts, and after contacting the authors through LinkedIn they were usually more than happy to include a link to my site in their articles.
I’m hoping to see continued growth to the point where I can monetise the site a bit, but so far it’s been a good learning experience and it hasn’t cost me anything but time.
There’s one link on there advertising Genesis Cloud – a cloud provider I’ve been using for training some machine learning models (their GPUs are very cheap!). I contacted them as a customer looking to promote their service, and they gave me a link I could put on my site. If they get any new paying customers through my link I get some credits to use on their cloud compute service.
I hope my experience is helpful to others trying to set up a simple site.
Here’s a recap of the tools I mentioned:
- Free, fast static site hosting: GitHub Pages
- Free mailing lists: Mailchimp
- Free analytics: Google Analytics
- Decent domains/paid web hosting: LCN
- Insight into search traffic: Google Search Console
- Free SEO tool trial: Moz Pro
And here’s my site, listing ongoing machine learning/data science competitions: mlcontests.com. Sign up to the mailing list for occasional (~once/month) updates on new competitions. All the code for the site is here.
For a more detailed guide on how to get set up your own blog with GitHub pages, I’d recommend this fast.ai article.